How machine learning is making an impact on media analysis
Artificial intelligence promises to dramatically change the way PR pros measure their campaigns. Here’s what the technology now allows—and where it is headed.
There is hardly any industry that has not jumped on the artificial intelligence and “big data” analytics bandwagon yet, but one notably lags: public relations and communication.
A possible reason for this is that PR is an inherently difficult discipline to quantify. Another is that the fields of AI which can provide transformational value to PR & comms—natural language processing (NLP), and natural language understanding (NLU) in particular—are yet to reach their optimal productivity. According to Gartner’s Hype Cycle of Natural Language Technologies, they still have some five to ten years to go until finding mainstream adoption.
Source: https://behavioralsignals.com/behavioral-signals-a-sample-vendor-for-natural-language-technologies/
The value of NLU, the part of NLP that deals with computers’ ability to comprehend the structure and meaning of human language, to PR pros lies in its application to automated reasoning, machine translation, news-gathering, text categorization, and large-scale content analysis.
Despite the challenges facing NLP, NLU presents significant opportunities for communication professionals and media analytics providers to achieve a granular analysis of textual data faster and more effectively.
For example, using machine learning for harnessing social media data can help identify unarticulated, unprompted, latent consumer needs, uncover platforms for category growth and integrate those with a digital activation strategy.
Decoding consumer language on social media
The key step to generating deep insights from consumer conversations on social media is leveraging NLP to create a business relevant taxonomy. Neither the software as a service (SaaS) NLP solutions nor the commercially available unsupervised deep learning algorithms can deliver this.
What we need is to create a much deeper taxonomy that can ladder-up to the main themes we have identified in the conversation. Take the example of sports drinks. At a first level, you will find topics related to consumption (such as health and taste). To uncover insights, we need to go deeper into a multi-layered NLP which is a combination of man and machine. What are the different sub-topics within health, what is it that consumers are talking about within each of these sub-subtopics? Are consumers talking about sustaining energy or sensory pleasure? What sports drinks are they using when talking of these actions? What are consumer emotional motivations? What are the feelings (sentiment) associated with these actions and what are the moments consumers are talking of with these actions? What are the benefits and concerns consumers share about sports drinks and what are the behavioural changes they are doing as a result of these concerns? All these help to build a detailed taxonomy.
In typical studies like the sports drinks case, taxonomy comprises 300-500 variables. In broader category studies, the taxonomy size can go up to 3,000+ variables.
No matter the category, it is this multi-layered NLP that provides the taxonomy that can be analyzed, interpreted and reconstructed to uncover meaningful insights, such as identifying opportunities for growth in a category.
One of the key components of NLP for taxonomy creation is uncovering the sentiment at scale, uncovering the sentiment associated with each individual construct (and not individual conversations) within each conversation.
The process of creating such a granular taxonomy is a combination of supervised and unsupervised machine learning. Though the principles are no different from how survey data is analyzed and interpreted, the sheer volume of data (in the range of 200,000 to 60 million+ conversations) and variables (300-3,000+) requires a different skill-set, new tools and a new mind-set.
Once a granular taxonomy and associated sentiment rules have been created using a combination of man and machine, deep learning algorithms can be trained for allocation of future data to business relevant taxonomy and insights. As deep learning algorithms are only as good as the basis on which the deep learning is trained, their specificity makes them more relevant and useful.
NLP’s top challenge and the road ahead
The biggest challenge in NLP is the shortage of training data. In projects like the one described above, it is rarely the case that more than a few thousand or a few hundred thousand human-labeled training examples can be used. However, modern deep learning-based NLP models see benefits from much larger amounts of data, improving when trained on millions (or billions) of annotated training examples.
To overcome this challenge, researchers have developed a variety of techniques for training general purpose language representation models using the enormous amount of unannotated text on the web (known as pre-training). The pre-trained model can then be fine-tuned on small-data NLP tasks like question answering and sentiment analysis, resulting in substantial accuracy improvements compared to training on these datasets from scratch.
The year 2018 was an inflection point for machine learning models handling text because it marked the release of BERT, an event described as marking the beginning of a new era in NLP.
BERT, which stands for Bidirectional Encoder Representations with Transformers, is a deep neural network architecture built upon the idea of learning a representation of language, called a language model, to predict tokens or sequences given a context.
BERT is a model that broke several records for how well models can handle language-based tasks. Soon after the release of the paper describing the model, the research team at Google offered open-source code for the model, and made available for download versions of the model that were already pre-trained on massive datasets. This is a momentous development since it enables anyone building a machine learning model involving language processing to use this powerhouse as a readily-available component, saving the time, energy, knowledge and resources that would have gone to training a language-processing model from scratch.
As a high level illustration of the way BERT makes sense of human language, we can run a BERT model trained on Wikipedia pages on the first two paragraphs of a Guardian article on the meat industry:
“Both the planet and US politics have heated up in tandem over recent decades, but few sectors have stewed in controversy quite like America’s beef industry. Four super-powered meatpackers control more than 80% of the US beef market, an extraordinary concentration of market power that the Biden administration is not happy about.
A recent executive action signed by the president aims to increase competition in the beef industry, with the White House noting that, over the past five years, “farmers’ share of the price of beef sales has dropped by more than a quarter – from 51.5% to 37.3% – while the price of beef has risen.”
Below are the resulting IPTC Media Topics BERT identified in the snippet with their respective frequencies:
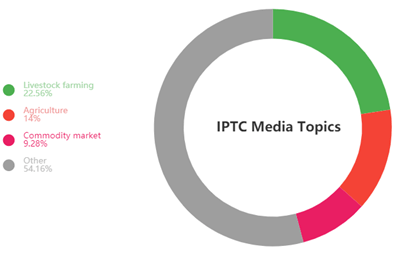
What is powerful about these pre-trained deep learning language models is that they provide a representation of how a language works and thus alleviate downstream tasks. For instance, we can train a classifier by adding a final layer to our pre-trained language model and finetune its last layer(s) to this specific task. Thus, we need less annotated data to achieve better results.
Whatever the opportunities, machine learning may not replace the art of communication and strategic media analytics anytime soon. In fact, an algorithm advanced enough to replace the instinct and creativity of humans may very well be the last thing mankind invents.
Georgi Ivanov is the director of global marketing at Commetric. A version of this article first appeared on the AMEC website.




